Over the years I have had the opportunity to fall in love with several software products: C, Linux, Java, .NET, HTTPD, Linux, and others (did I say Linux?), in addition to those mentioned there is also Lucene. Lucene is one of the many fantastic products of the Apache community. It is a library to manage (save, index and search) content. What makes Lucene superior to many other storage systems is its ability to scale.
A few years ago I had started working on an integration of Lucene within Matrix, unfortunately time was short and I put the project aside until I abandoned it to work on other aspects of the project. This year, taking advantage of the weeks of August, I had decided to take up again an aspect that was absolutely lacking in Matrix: the human-machine interaction. Until then the only possible interaction was “grep” and SQL. Obviously this did not make some tasks very comfortable and in some cases it was necessary to create scripts or programs to extract information and give it a decent form.
The situation was quite simple, I had a lot of information, stored in different locations, using different technologies. So I re-evaluated the old idea of storing everything in Lucene. The problem was that Lucene is great but I was missing a lot of components on top, including, above all, the graphical interface. So I started looking for products based on Lucene and realized that Elasticsearch was also based on Lucene. I had used Elasticsearch in the past in a couple of projects and honestly I knew little about it. So I spent a few days studying and then I moved on to practice. I installed a cluster with two nodes and started loading data.
I immediately started to upload the feeds of Zefiro (NRD), Scirocco (CTL) and Libeccio. In reality, the feeds produced by Libeccio are two: one contains the Whois queries related to the domains downloaded by Scirocco, the second contains the NRD derived from the processing of the Whois responses.
After a few weeks I also started uploading the analyses produced by Smith and subsequently the list of expired domains produced by Zefiro.
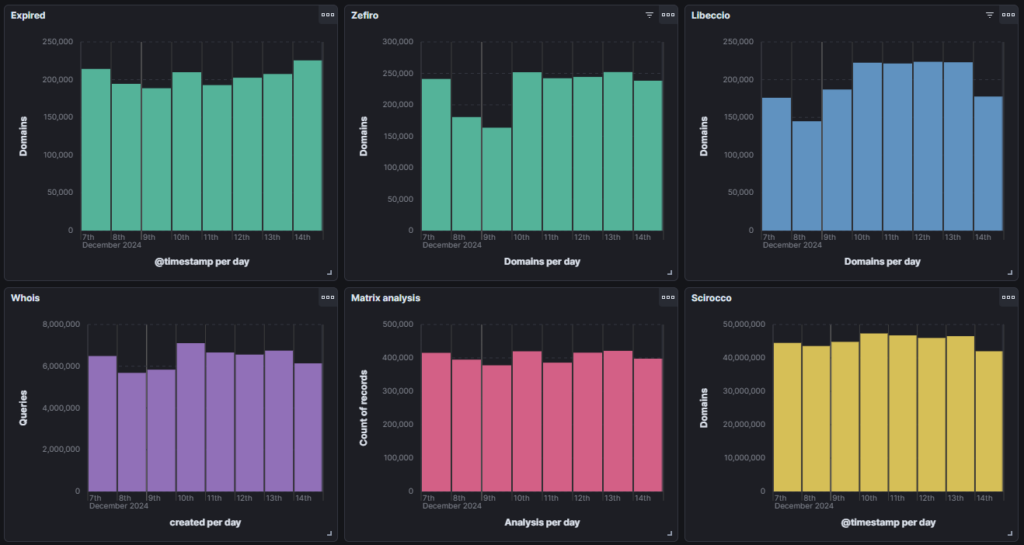
Adopting Elasticsearch has allowed me to easily analyze the data produced by Matrix and share this information with colleagues who use it for different use cases.
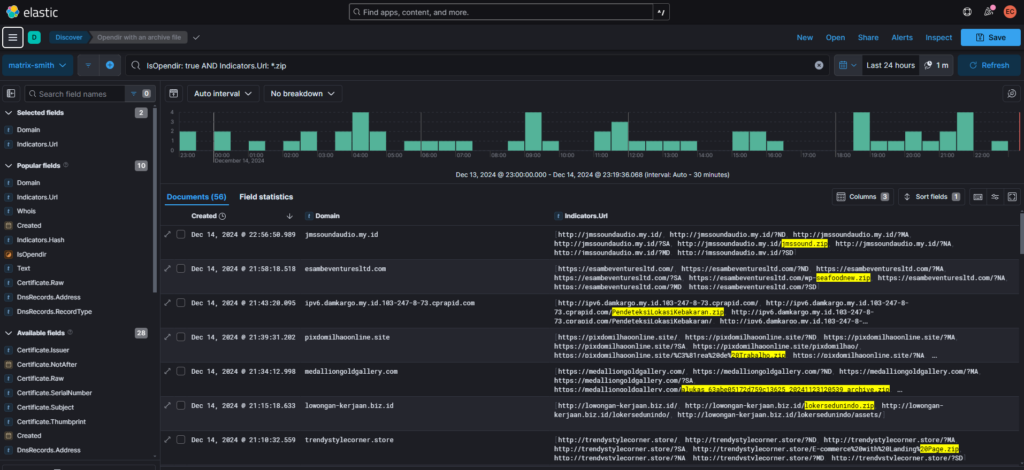
The loading methods used are mainly two: Filebeat and API. Using one of these two methodologies each subsystem loads its own dedicated index. To limit the size of each index (according to the documentation it is advisable to stay under 50GB) some indexes are rotated daily.
A few weeks ago I added a third node to the cluster and within a few hours the cluster completed the alignment procedure, completely automatically. Awesome.
Currently after two months of uploads into the cluster we have about 6B documents.
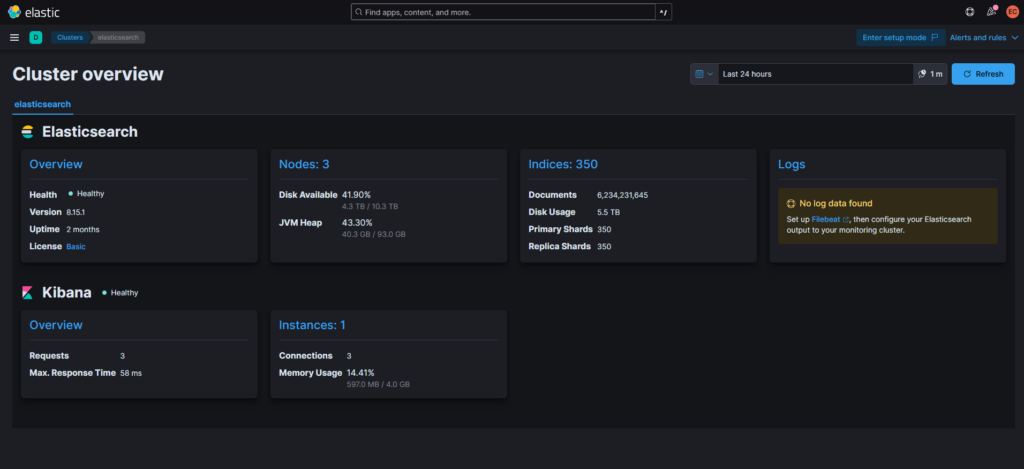
Searches continue to run within milliseconds and there have never been any performance issues. So far everything is running fine.
I tend to be very paranoid in adopting products and very often after careful analysis I tend to avoid doing so. Maybe it’s my age, maybe it’s my distrust of the average programmer, many times I realize that I do it quicker to develop, rather than find, understand, test and integrate available products. I understand the principle of not reinventing the wheel, but if attached to the wheel I find a circus with elephants, I prefer to reinvent the wheel. I don’t want to bring up every time the example of “J2EE” application servers to run some fucking JSP…
This is not the case: Elasticsearch is really cool!
Leave a Reply