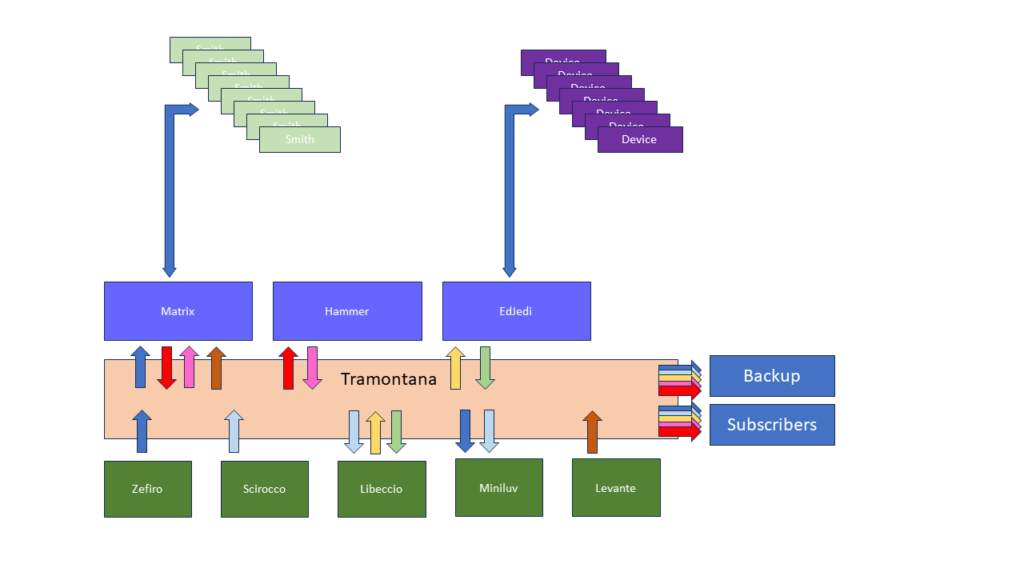
As mentioned in the first articles of this blog, Matrix was born with the idea of monitoring the Internet, not only in the classic sense used in the field of cyber security, but more broadly with a view to following trajectories to hypothesize trajectories and related scenarios. With this goal in mind, for years, I have been working on different fronts, one of the main ones being the detection of new entities, mainly Internet domains.
With the latest release a few weeks ago I am happy to note an important improvement: the detection time of a new registered Internet domain has become much shorter. When I say “detection of a new registered Internet domain” I am not referring to the classic feed that reports thousands of indicators per minute, like CTL or pDNS. I am referring instead to a timely notification that says “this domain was registered 15 minutes ago”.
The difference between having a streaming within which to go and look for something, compared to having a precise notification, for Matrix is substantial.
When I write “15 minutes” I do not write it by chance, 15-20 minutes is in fact the amount of time needed to receive the notification of a new domain on the Elasticsearch console. On the underlying feeds, those that populate the Elasticsearch indexes, this information arrives about 2-3 minutes earlier. It is therefore a matter of registering a domain on a provider and, with some exceptions, seeing it appear on one of the Matrix feeds in a few minutes. Obviously there are circumstances in which this does not happen and you have to wait a few hours.
Today I did a test, I registered three domains and all three arrived on the console between 15 and 20 minutes. I do not know if this is a great thing for everyone, for me it is and it is also very useful for the feed that I publish on Urlscan where I often see that the notifications arriving from Matrix are the first to identify some types of indicators, especially phishing sites.
Just to consider this article scientific and not marketing, I report here the “journey” of a domain in the bowels of the Matrix. From registration to being marked as a “new registered domain”.
The registered domain is “matrix-speed-test.com”
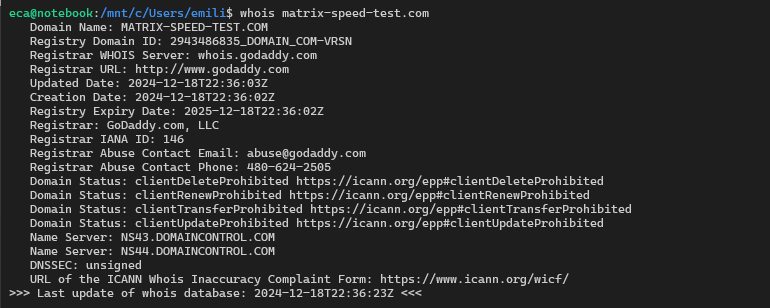
The one hour difference is obviously due to the time zone here in Italy.

The interesting aspect of this Kibana screenshot is not in the line extracted from the “scirocco” feed, this only reports the presence of the domain within the CTL feed. This feed is easily accessible and knowing the name of a domain it is easy to filter the feed. The interesting line is the one related to the “libeccio” feed: this feed in fact contains the newly registered domains.